-
联合分布与边缘分布:
FX(x)=∫−∞x∫−∞+∞f(u,v)dvduFY(y)=∫−∞y∫−∞+∞f(u,v)dudvfX(x)=∫−∞+∞f(x,y)dyfY(y)=∫−∞+∞f(x,y)dx
-
条件分布:
fX∣Y(x∣y)=fY(y)f(x,y)P(X≤x∣Y=y)≜FX∣Y(x∣y)=∫−∞xfX∣Y(u∣y)du
- 已知联合分布可以求得条件分布,反之则不能唯一确定
- 但边缘分布和条件分布可以结合求出联合分布
-
随机变量的独立性:
F(x,y)=FX(x)FY(y)
此时边缘分布完全确定联合分布
-
具有可加性的分布:同一类型分布的独立随机变量和的分布仍服从此类分布
-
泊松分布:若 X 和 Y 相互独立,且 X∼P(λ1),Y∼P(λ2),那么 X+Y∼P(λ1+λ2)
-
二项分布:若 X 和 Y 相互独立,且 X∼B(n,p),Y∼B(m,p),那么 X+Y∼P(n+m,p)
-
正态分布:若 X 和 Y 相互独立,且 X∼N(μ1,σ12),Y∼N(μ2,σ22),那么 X±Y∼N(μ1±μ2,σ12+σ22)
-
卡方分布:若 X 和 Y 相互独立,且 X∼χ2(n1),Y∼χ2(n2),那么 X+Y∼χ2(n1+n2)
-
具有无记忆性的分布:几何分布、指数分布
P(X>s+t∣X>s)=P(X>t)
-
极值的分布:设 X1,X2,⋯,Xn 相互独立,且 Xi∼FXi(xi),i=1,2,⋯,n
M=1≤i≤nmax{Xi},N=1≤i≤nmin{Xi}
则
FM(z)=i=1∏nFXi(z)FN(z)=1−i=1∏n(1−FXi(z))
-
切比雪夫不等式:设随机变量 X 的方差 D(X) 存在,则对于任意实数 ϵ>0,
P(∣X−E(X)∣≥ϵ)≤ϵ2D(X)
-
依概率收敛:设 Y1,Y2,⋯,Yn,⋯ 是一系列随机变量,若 ∀ϵ>0 有
n→∞limP(∣Yn−a∣≥ϵ)=0
则称随机变量序列 Y1,Y2,⋯,Yn,⋯ 依概率收敛于常数 a
- 含义:随机变量序列 Yn 收敛于常数 a 的概率趋于 1
-
大数定律的定义:若随机变量序列 X1,X2,⋯,Xn,⋯ 满足:对 ∀ϵ>0 有
n→∞limP(n1k=1∑nXk−n1k=1∑nE(Xk)≥ϵ)=0
称该随机变量序列服从大数定律,即
n1k=1∑nXkPn→∞n1k=1∑nE(Xk)
- 也就是说,当样本数量足够大时,样本均值与数学期望充分接近
-
伯努利大数定律:设 nA 是 n 次独立重复试验中事件 A 发生的次数,p 是每次试验中 A 发生的概率,则 ∀ϵ>0 ,有
n→∞limP(nnA−p≥ϵ)=0
即
nnAPn→∞p
-
切比雪夫大数定律:设随机变量序列 X1,X2,⋯,Xn,⋯ 两两不相关,它们的方差存在,且有共同的上界,即
ρXiXj=0,(i=j),E(Xk)=μk,D(Xk)=σk2≤σ2,k=1,2,⋯
则该序列服从大数定律,即对任意正数 ϵ>0 ,有
n→∞limP(n1k=1∑nXk−n1k=1∑nμk≥ϵ)=0
-
辛钦大数定律:设 X1,X2,⋯,Xn,⋯ 相互独立,服从同一分布,且具有相同的数学期望 E(Xk)=μ,k=1,2,⋯ ,则对任意正数 ϵ>0 ,有
n→∞limP(n1k=1∑nXk−μ≥ϵ)=0
即
n1k=1∑nXkPn→∞μ
-
独立同分布中心极限定理:设随机变量序列 X1,X2,⋯,Xn 为相互独立同分布的,它们的期望、方差都存在,
E(Xk)=μ,D(Xk)=σ2>0,k=1,2,⋯
则对于任意实数 x,
n→∞limP(nσ∑k=1nXk−nμ≤x)=2π1∫−∞xe−2t2dt
这表明 n 足够大时,
nσ∑k=1nXk−nμ∼ 近似 N(0,1)
即
k=1∑nXk∼ 近似 N(nμ,nσ2)
-
棣莫弗-拉普拉斯中心极限定理:设 Yn∼B(n,p),0<p<1,n=1,2,⋯ ,则对任一实数 x ,有
n→∞limP(np(1−p)Yn−np≤x)=2π1∫−∞xe−2t2dt
即 n 足够大时,
Yn∼ 近似 N(np,np(1−p))
-
正态分布:若 X1,X2,⋯,Xn 相互独立,且 Xi∼N(μi,σi2) ,则
i=1∑naiXi∼N(i=1∑naiμi,i=1∑nai2σi2)
特别地,若 Xi∼N(μ,σ2) ,则
Xˉ=n1i=1∑nXi∼N(μ,nσ2)
-
χ2 分布:设 X1,X2,⋯,Xn 相互独立,且 Xi∼N(0,1) ,则
i=1∑nXi2∼χ2(n)
- E(χ2(n))=n,D(χ2(n))=2n
- 当 n→∞ 时,χ2(n)→ 正态分布
-
t 分布:设 X∼N(0,1),Y∼χ2(n),X,Y 相互独立,则
T=Y/nX∼t(n)
- t 分布的概率密度是偶函数
- 当 n→∞ 时,t(n)→ 正态分布
-
F 分布:设 X∼χ2(m),Y∼χ2(n),X,Y 相互独立,则
F=Y/nX/m∼F(m,n)
- 若 F∼F(m,n), 则 F1∼F(n,m)
- F1−α(n,m)=Fα(m,n)1
-
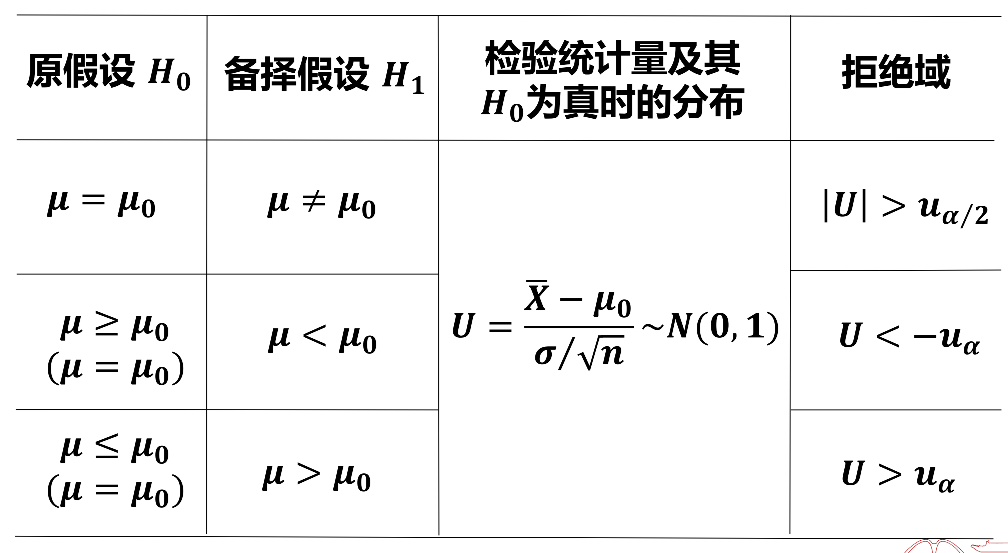
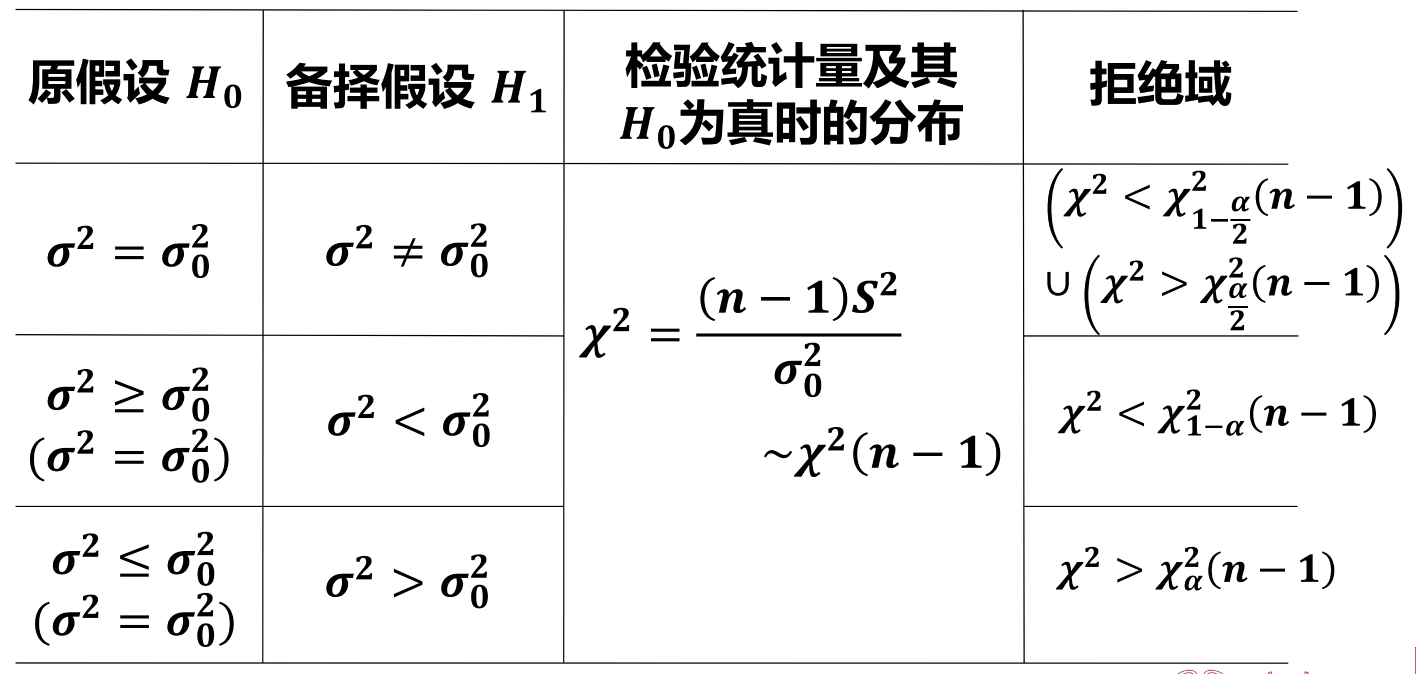
一个正态总体:
σ/nXˉ−μ∼N(0,1)
S/nXˉ−μ∼t(n−1)
σ2(n−1)S2=i=1∑n(σXi−Xˉ)2∼χ2(n−1)
i=1∑n(σXi−μ)2∼χ2(n)
-
两个正态总体:
mσ12+nσ22(Xˉ−Yˉ)−(μ1−μ2)∼N(0,1)
S22/σ22S12/σ12∼F(m−1,n−1)
若 σ1=σ2,则
m1+n1m+n−2(m−1)S12+(n−1)S22(Xˉ−Yˉ)−(μ1−μ2)∼t(m+n−2)